Геймченджер и угроза человечеству. Что важно знать о новой модели DeepSeek
The Bell
DeepSeek обвалила акции Nvidia на $600 млрд, а стоимость всех входящих в индекс Nasdaq 100 компаний упала почти на $1 трлн. Почему инвесторы посчитали, что молодой AI-стартап из Ханчжоу — это реальная угроза для всего американского хайтека? И что на самом деле известно о новом «рассуждающем» китайском ИИ. Рассказываем главное, что известно об R1 от DeepSeek на этот момент.
Что известно о DeepSeek
DeepSeek — это молодая китайская AI-компания, спин-офф хедж-фонда High-Flyer, использующего ИИ для торговли акциями. За прошлый год стартап, появившийся лишь в 2023-м, представил несколько больших языковых моделей, но фурор произвела только выпущенная в конце прошлой недели «рассуждающая» R1, которая умеет строить цепочки размышлений, как o1 от OpenAI, — и делает это как минимум не хуже, а иногда и лучше конкурента.
Однако, в отличие от OpenAI, DeepSeek сделала R1 открытой — она доступна по модели open-weight (то есть с открытыми весами, это значит, что известны параметры, по которым обучалась модель, но конкретные данные, которые использовала компания, не публикуются). Кроме того, DeepSeek опубликовала технический отчет, а значит, результаты исследований китайской компании могут взять на вооружение разработчики по всему миру — и это может сильно повлиять на мировой баланс AI-сил.
Протестировать R1 любой желающий может бесплатно на сайте или в приложении, а доступ к API обойдется в десятки раз дешевле, чем у OpenAI: $0,14 за обработку млн токенов против $2,4 у o1.
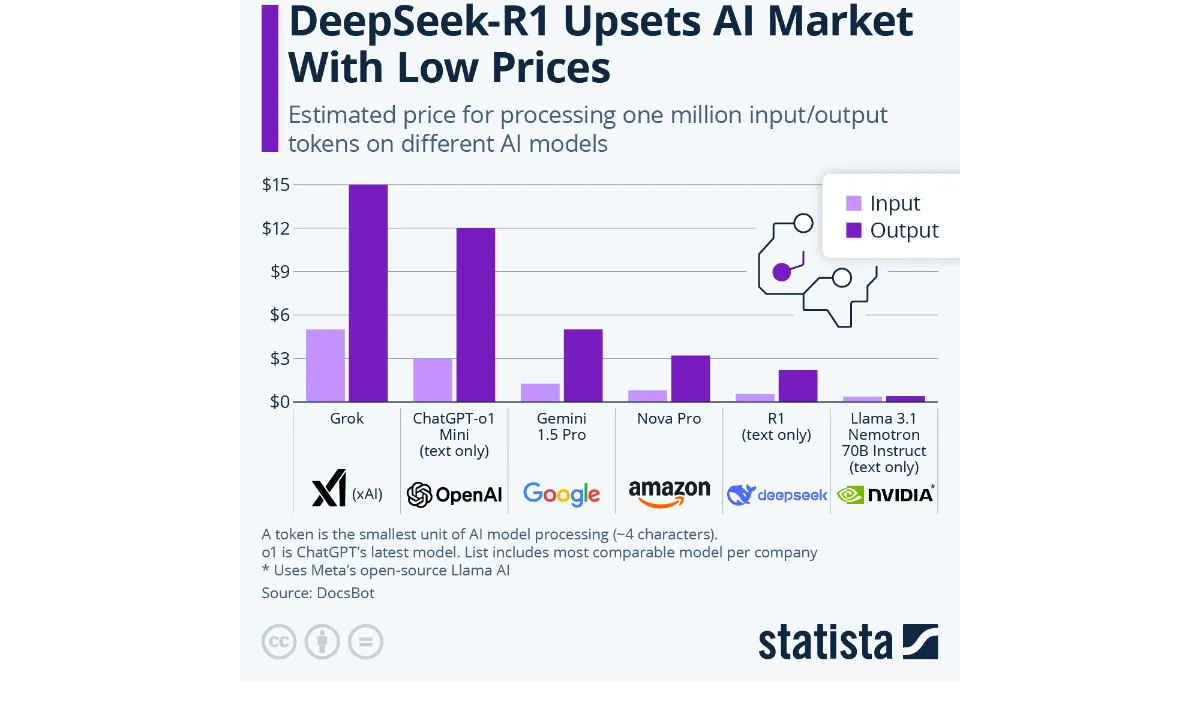
Сколько стоила R1
Широко разошедшаяся цифра в $6 млн, которые якобы стоило обучение модели, на самом деле не особенно информативна. Она получилась из оценки потраченных ресурсов на обучение другой модели компании — V3, и не включает в себя ни расходы на предыдущие разработки и эксперименты, ни на дообучение, которое потребовалось для появления R1. В реальности речь может идти скорее, как минимум, о десятках миллионов долларов.
Но это все равно меньше, чем у конкурентов. DeepSeek снизила затраты на обучение, потому что сумела обучить модель, используя меньше вычислительных ресурсов и более дешевые чипы. Кроме того, компания обучала R1 методом чистого обучения с подкреплением RL, а не обучением с учителем SFT. Supervised Fine-Tuning — это когда модель учат на заранее подготовленных данных с известными правильными ответами. Reinforcement Learning — это когда модель учится на собственном опыте, получая награды или наказания за свои действия. И этот метод — дешевле.
На новости о стоимости обучения модели, по всей видимости, и отреагировал рынок. DeepSeek показала, что для создания передовых моделей может потребоваться гораздо меньше вычислительных ресурсов и дорогостоящих чипов — а это поставило под вопрос стратегию американского бигтеха, который тратит на инфраструктуру и чипы миллиарды долларов.
Однако многие эксперты и аналитики полагают, что рынок отреагировал слишком остро: на самом деле, непонятно, как именно появление DeepSeek и будущих подобных моделей повлияет на рынок.
В связи с этой ситуацией сразу трое собеседников The Bell в разных AI-компаниях припомнили «парадокс Джевонса» — экономическое явление, при котором технологический прогресс, повышающий эффективность использования ресурса, приводит не к снижению, а к увеличению его общего потребления. Если так, то спрос на те же чипы Nvidia теперь может только вырасти. А инвестор Фрэнк Михэн по этому поводу написал, что компании, продающие инфраструктуру, вроде AWS или экс-«Яндекса», NebiusAI, от всего происходящего выиграют, потому что разработчиков, которым нужны будут их услуги, станет больше.
Кому еще угрожает DeepSeek
Если технооптимисты за релизом открытой R1 увидели возможности для будущих AI-стартапов по всему миру, то скептики подметили новые угрозы, к которым ведет бесконтрольное распространение «рассуждающего» ИИ. А учитывая, что в США ИИ — это новый национальный проект, эта гонка может привести к неконтролируемым и пугающим последствиям.
Например, Platformer обращает внимание, что «гонка вооружений» в ИИ — настоящий кошмар специалиста по этическим проблемам искусственного разума. «Чем больше людей убеждены, что это матч на выбывание с Китаем, тем менее безопасными будут создаваемые ИИ, — пишет автор — Если какая-нибудь ИИ-лаборатория вдруг создаст и выпустит в обращение сверхразумный ИИ, у нас не будет ни уверенности, что его ценности и желания соотносятся с человеческими, ни плана, что делать дальше».
Примерно о том же рассуждает пишущий об ИИ техноблогер Цви Мовшовиц. Он указывает, что основатель DeepSeek Лян Вэньфэн не видит такой проблемы в принципе, а многие энтузиасты что в Китае, что за его пределами это поддерживают. «Они серьезно верят, что лучшее, что мы можем сделать — создать кого-то умнее себя с максимумом способностей, раздать его кому попало и пребывать в уверенности, что все хорошо закончится», — пишет он.
Кроме того, у новой модели DeepSeek также есть проблемы, свойственные всем нейросетям: например она часто «галлюцинирует» и выдает совершенно неверные ответы. Кроме того, все сервера у компании, естественно в Китае, а сама она собирает о своих пользователе практически всю информацию, какую может, включая паттерны нажатий клавиш. А еще нейросеть цензурируется: по крайней мере на английском R1 отвечает на идеологически проблемные вопросы в соответствии с разрешенными в Китае воззрениями. Например, модель называет ложными обвинения в нарушении прав человека в Синьцзян-Уйгурском автономном районе и не признает существования цензуры за «великим файрволом».