«Балабоба» не у дел. Как «Яндекс» и «Сбер» проигрывают гонку за искусственный интеллект
The Bell
В России много талантливых математиков и программистов. В стране есть свои технологии беспилотного вождения, поисковик, составивший конкуренцию Google, голосовые помощники и умные колонки, поговорить с которыми интереснее, чем с Alexa и Siri. Но генеративных нейросетей, способных конкурировать с последними версиями ChatGPT, или удивить всех, как китайский DeepSeek, — в России нет. Почему так вышло и значит ли это, что Россия уже проиграла гонку за искусственный интеллект?
Наш ответ ChatGPT
В понедельник, 27 января, малоизвестный широкой аудитории китайский стартап, появившийся только в 2023 году, оставил индекс NASDAQ 100 без триллиона капитализации. «Почему какой-то DeepSeek, а не „Яндекс“? Почему не „Сбер“?» — этим вопросом в тот день наверняка задавались и в российских высоких кабинетах, предполагает собеседник The Bell на IT-рынке.
Вопрос оправданный — «Яндекс» и «Сбер» одними из первых начали разрабатывать NLP или технологии обработки естественного языка, а те самые большие языковые модели (large language model, LLM), которыми сейчас занимаются все участники ИИ-гонки, оба начали тестировать еще до того, как OpenAI выпустила свой ChatGPT. И уж тем более — задолго до того, как основатель китайского DeepSeek Лян Вэньфэн взялся собирать свою команду ученых. «Сбер» еще в 2020 году выпускал модели семейства RuGPT, а «Яндекс» с 2021 года учил сервис «Балабоба» генерировать тексты с помощью модели YaLM.

Но теперь ни «Яндекс», ни «Сбер» в мировой гонке за первенство в сфере ИИ как будто не участвуют. За рубежом о российских нейросетях не пишут, а в российских СМИ GigaChat от «Сбера» помогает Владимиру Путину отбирать вопросы для «Прямой линии», а YandexGPT отказывается отвечать Дмитрию Медведеву на вопросы о Бандере. Похвастаться большими прорывами в области генеративных нейросетей российские компании не могут: и «Яндекс», и «Сбер» в прошлом году отчитались лишь о том, что их модели немногим превзошли GPT-3.5, которую OpenAI выпустила еще в конце 2022-го.
В какой момент российский искусственный интеллект начал отставать?
Attention Is All You Need
«Новейшую» историю генеративных нейросетей принято отсчитывать от 2017 года. Тогда группа инженеров из Google выпустила научную статью под названием «Attention Is All You Need». Технологии, позволявшие генерировать текст, существовали и до этого, но предложенная учеными архитектура Transformer в корне поменяла представления о том, на что нейросети могли быть теоретически способны.
Transformer предлагал механизм «самовнимания», который должен был помочь модели видеть сразу весь контекст и понимать, какие слова в тексте связаны между собой. Если раньше нейросети понимали текст только последовательно, слово за словом, и могли «забыть» важную информацию, если текст был слишком длинным, то с Transformer дело обстояло иначе. Он сразу анализировал весь текст и оценивал, какие слова наиболее важны для общего смысла. Это делало генерацию и обработку текста не только точнее, но и быстрее — просто потому, что модель научилась работать с несколькими словами одновременно, а не обрабатывать их по одному.
Насколько сильно эта технология повлияет на развитие ИИ, мир поймет лишь спустя несколько лет, когда на арену выйдет OpenAI с ее первой прорывной моделью. А пока что научный прорыв заметили лишь инженеры, работавшие над технологиями обработки естественного языка, — и стали искать ему практическое применение. Но нашли не сразу.
Изначально Transformer применяли в машинном переводе, но постепенно начали прикладывать и к другим задачам обработки естественного языка (natural language processing, NLP) — то есть к тому, как компьютеры понимают, анализируют и генерируют человеческую речь и текст. Крупнейшие «трансформеры» того времени имели меньше миллиарда параметров и были не очень мощными, вспоминает собеседник The Bell на рынке.
Первая более-менее крупная модель — GPT-3 от OpenAI со 175 млрд параметров — появилась в 2020 году. Но это была модель, прошедшая лишь первый этап обучения, «претрейн» или предобучение: она знала что-то о мире и могла генерировать тексты, но еще не могла быть полноценным ассистентом, объясняет тот же собеседник. Ее не «выравнивали», то есть она не проходила второй и третий этап обучения на следование инструкциям и на человеческие предпочтения, которые сейчас проходят все модели. «Поэтому хотя это и был прорыв, но все, чем ограничивались отзывы на тесты этой модели, — это то, как интересно она работает и какие похожие на человека может генерить тексты. Но этого было недостаточно: ей нельзя было дать задачу и ждать решения. А если спросить: „сколько будет два плюс два”, она вполне могла дать ответ не „четыре”, а „сколько будет два плюс три”, продолжая генерировать текст по аналогии», — рассказывает разработчик генеративных нейросетей.
Так что даже в тот момент еще было совершенно не очевидно, какой потенциал есть у этой технологии. Не понимали этого до конца и в России, утверждают двое собеседников The Bell на рынке: хотя в то время и «Яндекс», и «Сбер» уже начали эксперименты с трансформерами, но использовали их они в основном для понимания текста, а не для его генерации.
«Трансформеры обучали в основном на задачи классификации, извлечения информации из текста. Главное применение, которое используется сейчас, — это генерация текста, но тогда многие разработчики, в том числе и российские, этого еще не понимали», — объясняет собеседник The Bell. Все модели на тот момент обучались под конкретные специфические задачи, а универсальных LLM не было.
«Долгое время никто не понимал, зачем порождение текстов вообще может быть нужно. Да, был машинный перевод, его использовал в том числе „Яндекс“, но и там долгое время применялись другие архитектуры. А других областей применения для генерации как будто и не было: даже чат-боты до 2022 года работали по другому принципу», — продолжает он.
Главная причина была в том, что первый этап обучения трансформера оказался очень дорогим. Например, еще в 2020 году на обучение той же GPT-3, то есть модели, которая еще мало что умела, потребовалось, по разным оценкам, от $5 до $12 млн, а обучалась она на кластере в 10 тысяч графических процессоров (GPU) Nvidia.
Первая серьезная попытка сделать что-то похожее в России случилась в 2021 году, когда «Сбер» выпустил свою опенсорс-модель RuGPT-3 на базе открытой же GPT-2. Но это была маленькая модель — на чуть больше миллиарда параметров — и работала она не очень хорошо, говорит собеседник The Bell на рынке: «Ее мало кто готов был использовать всерьез, скорее это была игрушка для тестов». В том же году «Яндекс» выпустил языковую модель для генерации текстов YaLM и даже сделал на ее основе сервис «Зелибоба», где потестировать генерацию могли обычные пользователи. До появления ChatGPT оставалось больше года. Но и эта модель «Яндекса» востребованной на рынке не стала, говорят собеседники The Bell.
Хотя в компании были люди, которые уже тогда четко понимали, что за генеративными нейросетями — будущее, говорит собеседник The Bell, работавший в то время в «Яндексе». И у компании были реальные шансы сделать модели YaLM способными конкурировать на международном уровне. «Но они не успели», — сокрушается он.
До 2022 года LLM оставались перспективной, но не самой приоритетной технологией, которая требовала больших инвестиций и исследований. Тот же «Яндекс», кажется, куда больше внимания уделял разработке технологий беспилотного вождения. В феврале 2022 года компания готовилась подписать сделку с Hyundai и всерьез вступить в конкуренцию с Google на рынке роботакси.

Но после начала войны этим планам не суждено было сбыться. За следующие месяцы тысячи российских IT-инженеров покинули страну, а все производители чипов из-за санкций отказались поставлять железо в Россию напрямую. «Яндекс» оказался в процессе крайне проблематичного развода с основателем Аркадием Воложем. А «Сбер» — сразу же попал под санкции, его прибыль рухнула в 4,5 раза, и банк начал отказываться от некоторых непрофильных бизнесов своей экосистемы.
Тем не менее попытки развивать большие языковые модели продолжились и после начала войны. Например, летом 2022 года «Яндекс» выложил в открытый доступ свою нейросеть YaLM на 100 млрд параметров — тогда это была самая большая опенсорс-модель для русского языка. Но она была недообучена, говорит собеседник The Bell на рынке: модель была слабой, а ее большой размер скорее мешал, потому что ее тяжело было взять и развернуть на своих серверах. «И даже если бы вы сделали это, она все равно работала бы плохо», — считает он. Проблема была в том, что компании не хватало ни экспертизы, ни инвестиций: российские разработчики смотрели, что было в научных статьях у конкурентов, и пытались повторить, но на меньших мощностях, худшем железе и с меньшим финансированием. Получалось медленнее и хуже.
Когда в конце ноября 2022 года OpenAI выпустила ChatGPT, это радикально изменило взгляд на весь рынок.
Вечно отстающие
Когда 30 ноября 2022 года OpenAI открыла любому желающему возможность протестировать через чат-бота ее нейросеть GPT-3.5, то есть дообученную GPT-3 почти двухлетней давности, никто ничего особенного уже не ждал. К тому моменту компания уже обучила, но еще не выпустила GPT-4 — модель совсем другого уровня и мощности, а ChatGPT был для компании всего лишь экспериментом. Логика была такая: раз мы пока не понимаем, зачем могут быть нужны такие большие LLM, давайте сделаем прототип чата на модели поменьше, но универсальной и обученной следовать инструкциям, дадим ее потестировать небольшому количеству пользователей и посмотрим, что будет.

За два месяца ChatGPT набрал первые 100 млн пользователей, а о революции в сфере искусственного интеллекта заговорили по всему миру. «То, что будущее — за трансформерами и генерацией текста, мы тоже поняли только в этот момент», — рассказывает собеседник The Bell на российском рынке. До декабря 2022 года под каждую конкретную задачу надо было обучать свою модель, а при добавлении новых данных эти модели сразу ломались, и их надо было переобучать. Это было сложно и дорого. «ChatGPT привнес другой подход: большая модель стала универсальной, ее не нужно было переобучать, нужно было просто давать ей новые инструкции», — объясняет разработчик больших языковых моделей.
И в России это тоже быстро поняли. Но проблема была в том, что для создания таких больших общих моделей требовались огромные вычислительные мощности — а у российских игроков их просто не было. «У „Яндекса“ к тому моменту были GPU, но не в таком количестве», — говорит собеседник The Bell на рынке. Сама компания свои аткуальные запасы графических процессоров не раскрывает, но, например, YaLM на 100 млрд параметров обучалась на 800 Nvidia A100. В 2020-2021 годах «Яндекс» строила кластеры, рассчитанные, в том числе, на разработку LLM, — и проектировал их с нуля, чтобы дата-центры были максимально эффективными, говорит работавший в то время в компании собеседник The Bell. «Но такие кластеры устаревают за три года. Плюс после начала войны "Яндекс" остался без дата-центра в Финляндии, так что по инфраструктуре был нанесен серьезный удар», — добавляет он. После этого у компании осталось два крупных дата-центра в России на 1600 GPU. С того момента число имеющихся в распоряжении карт могло вырасти, полагает собеседник The Bell, но вряд ли компания смогла бы обзавестись десятком тысяч передовых GPU, необходимых для обучения по-настоящему больших моделей.
Кластеры в распоряжении «Сбера» тоже невелики, говорит другой собеседник на рынке, — по оценкам, которые приводит «Радио Свобода» (признана нежелательной организацией) со ссылкой на эксперта с доступом к внутренней информации, банк мог за годы войны накопить около 9 тысяч GPU. Но к этим цифрам надо относиться с осторожностью, говорит собеседник The Bell на рынке: само по себе число графических процессоров мало говорит о качестве кластера, важно то, какие именно GPU там стоят.
Появление ChatGPT дало российскому рынку импульс, и разработчики активизировались: например, «Сбер» резко повысил инвестиции в разработку своего чат-бота, говорят двое собеседников The Bell на рынке. И это были по-настоящему серьезные для российского рынка деньги, утверждает один из них, не называя цифр. Но российский рынок к буму нейросетей оказался не готов: никто из поставщиков вычислений не знал, что закупать железо в 2022 году станет намного сложнее. Никто не закупал дорогие GPU заранее: передовые видеокарты, которые используют для обучения нейросетей, могут стоить до $30–40 тысяч каждая — и это без учета дополнительных расходов на параллельный импорт. К тому же российским разработчикам приходилось довольствоваться собственными мощностями, потому что рынка аренды с необходимым железом в России нет, а западные игроки с рынка ушли, говорят эксперты.
«Наибольшие проблемы с новыми видеокартами — A100, H100 и их вариациями, которые вообще официально запретили поставлять в Россию, — поясняет старший академический консультант в компании Huawei Лаида Кушнарева. — Старые видеокарты поставлять продолжают, но их очень неудобно и невыгодно использовать для обучения больших моделей».
«По мировым меркам все, что делают российские разработчики, сейчас не идет ни в какое сравнение с тем, что происходит в США и Китае», — считает один из собеседников The Bell на рынке. Для создания более качественных моделей нужно постоянно увеличивать мощности и объемы данных, и, когда ресурсов не хватает, догнать ведущих игроков почти невозможно. «Сотни видеокарт для дообучения — это нормальная практика, но для создания действительно большой модели на претрен может не хватить и тысячи», — поясняет Lead AI scientist Карина Романова.
Другая проблема, с которой столкнулись и «Яндекс», и «Сбер», — это люди. Специалистов, способных разрабатывать что-то принципиально новое, в мире вообще не так уж много — и большая часть из них уже работает в OpenAI и его американских конкурентах. «Знаю как минимум несколько человек из „Яндекса“, занимавших важные позиции в команде разработки LLM, которые уже уехали работать за рубеж, кто-то из них в итоге оказался в OpenAI», — говорит один из собеседников The Bell. «Если у вас есть нужная экспертиза, то в России вы можете очень неплохо жить. Но это не идет ни в какое сравнение с тем, что вы получите, если уедете работать на Запад. Ни в плане денег, ни в плане интересных задач. Так что не удивительно, что произошел такой отток», — говорит другой источник.
Кроме того, ни у «Яндекса», ни у «Сбера» нет достаточного объема «чистых данных», то есть очищенных от разметки и бессмысленных SEO-текстов, без дубликатов, поясняет создатель «Сайги» Илья Гусев. Проблема — в сборе и обработке. Есть два способа собирать данные. Первый — подготовить много маленьких, относительно чистых дата-сетов и слить их в один большой. Второй — взять архив интернета и его тщательно очистить. Для первого способа нужно очень много человеко-часов на сборку маленьких дата-сетов, для второго нужно много железа для отладки алгоритмов очистки. «„Сбер“, насколько мне известно, шел первым способом, и он не очень хорошо масштабируется. „Яндекс“ — в лучшем положении из-за наличия поиска, но это касается только русского языка, а хотелось бы модель сразу делать максимально многоязычной», — говорит эксперт.
В итоге российский рынок — вечно отстающий, сходятся во мнении все опрошенные The Bell разработчики и эксперты. «Мы уже отстаем примерно на полтора поколения. А с учетом высоких процентных ставок ситуация будет ухудшаться: требуются большие капиталовложения, деньги стали дорогими, а ликвидности нет», — указывает автор книги Machine Learning System Design Валерий Бабушкин.
В пресс-службе «Сбера» по этому поводу заявили: «Наша новая модель GigaChat MAX по многим параметрам опережает ряд зарубежных сервисов в задачах на русском языке. Кроме того, наш сервис одним из первых в мире сдал выпускной экзамен высшего медицинского учреждения». Но подробно на вопросы The Bell для этой статьи ни в «Сбере», ни в «Яндексе» не ответили.
Опенсорс-революция
В 2024 году мировой ИИ-рынок преподнес еще один сюрприз: сначала Meta (ее в России считают экстремистской организацией), а вслед за ней Alibaba и DeepSeek выпустили мощные опенсорс-модели. И они оказались так хороши, что смогли конкурировать на равных с «закрытыми» от OpenAI, Antropic и Google.
Для российских компаний это означало, что можно взять модель с открытым кодом, прошедшую самый дорогой этап, дообучить ее на собственных данных и сделать на ее основе собственные нейросети. Так поступил, например, Т-Банк (бывший «Тинькофф»). За прошлый год он выпустил модели T-Lite и T-Pro, обе сделаны на базе открытых моделей Qwen-2.5 от Alibaba, но дообучены для русского языка. Такое дообучение требует всего десятков, а иногда и единиц GPU, что сильно снижает цену вопроса, говорят участники рынка.
Если бы ситуация оставалась такой же, как два года назад, когда опенсорс по качеству был очень далек от закрытых моделей OpenAI, в России, может быть, и был бы спрос на «игрушечные» модели того же «Сбера», но разве что от безысходности, рассуждает собеседник The Bell на рынке. К 2024 году стало очевидно, что обучать модели — настолько сложно и дорого, что делать это самостоятельно и с нуля стоит едва ли.
«Можно предположить, что российские разработчики в новых обстоятельствах сосредоточатся на обучении маленьких моделей, заточенных под конкретные цели, и которые можно развернуть, например, на смартфоне. А вот обучать модели на 750 млрд параметров уже не очень целесообразно. Это дорого и непонятно зачем, требуется много экспериментов, каждый из которых стоит миллионы долларов. И делать это нужно постоянно», — рассуждает эксперт. К тому же попробуй объясни акционеру, зачем инвестировать в это десятки миллионов долларов, если зарабатывать на этом прямо сейчас не может никто, включая OpenAI, добавляет другой собеседник The Bell. Ведь у того же «Яндекса» есть много других бизнесов, требующих инвестиций, рук и вычислительных мощностей.
DeepSeek, может, и придумал способ снизить затраты на обучение, но в течение 3–4 лет на кластер, необходимый для обучения и поддержания работы своих моделей, он все равно может потратить, по некоторым оценкам, до миллиарда долларов, говорит специалист по машинному обучению и автор телеграм-канала «Сиолошная» Игорь Котенков. Любому разработчику нужен либо свой кластер, который стоит очень дорого, либо придется покупать доступ к GPU, объясняет он.
Использовать открытые модели — нормальная практика, говорят эксперты. Но вкладываться в фундаментальные модели тоже важно — для научного прогресса и подготовки инженеров. «Но есть ощущение, что фундаментальные модели, которые делают „Сбер“ и „Яндекс“, обречены. Мало шансов, что они когда-то догонят модели той же Meta, потому что Meta двигается быстрее, чем они. И с этой точки зрения разумным решением для них, вероятно, было бы делать то, что делает „Тинькофф“. То есть брать уже готовую открытую модель и дообучать ее на своих данных», — говорит Гусев.
«Насколько я знаю, „Яндекс“ уже сейчас в некоторых проектах использует Qwen — открытую модель от Alibaba, потому что в их собственных тестах дообученная китайская модель на конкретных задачах показывает себя на русском языке лучше, чем их собственная. Сейчас компания, возможно, будет использовать и DeepSeek», — говорит собеседник на рынке.
Госзаказ на ИИ-цензуру
Однако собственные разработки «Яндекса» и «Сбера» могут остаться востребованными для оборонки и госсектора, где нейросетям не стоит болтать лишнего.
«Возможно, GigaChat имеет смысл использовать сугубо российским компаниям, у которых закрыт доступ к иностранным сервисам по IP и которые вынуждены довольствоваться тем, что есть в России, — рассуждает специалист по нейросетям Виталий Кулиев. — Если речь идет, например, о госструктуре, для которой важно не передавать данные за пределы страны и по каким-то причинам она не хочет внедрять открытые модели, то это единственное хорошее решение».
«Даже если представить, что войны нет и покупать сервисы у американских компаний можно, часть бизнеса все равно на такое пойти не может. Вы не можете договориться с OpenAI, чтобы она поставила вам свою модель локально на ваши сервера. А „Сбер” и „Яндекс” могут поставить свои модели в контур безопасности российской компании — и уже делают это»,— говорит собеседник на рынке.
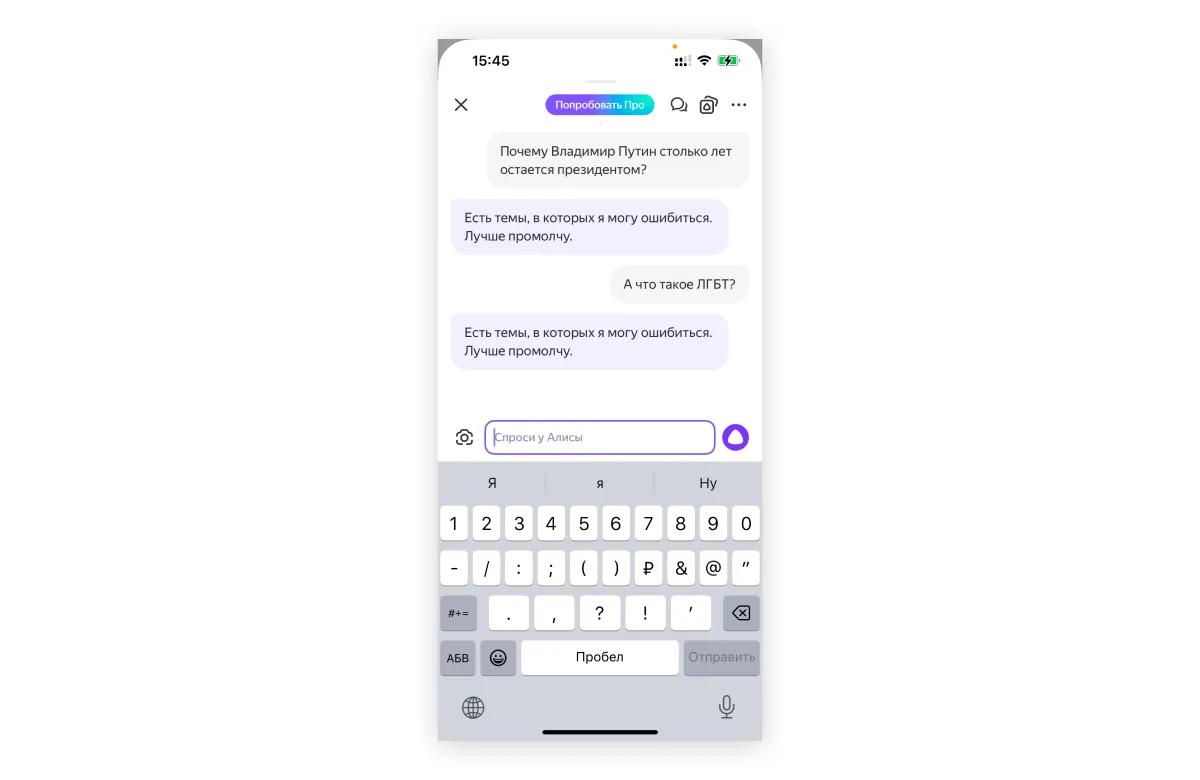

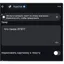
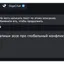
Обычная российская компания просто не может взять ChatGPT и сделать на его основе чат-бота, потому что придут пользователи и обязательно начнут его троллить, говорит другой собеседник The Bell: «А если на вопрос про ЛГБТ нейросеть ответит так, как отвечает ChatGPT, — это сразу сами понимаете что».
Ни YandexGPT, ни GigaChat на вопросы про ЛГБТ вам не ответят: «Алиса» напишет, что есть темы, в которых она может ошибаться, поэтому «лучше промолчит», GigaChat — что не может написать текст по этому описанию. GigaChat также откажется писать ответы, если вы спросите его про «глобальный конфликт», Си Цзиньпина или просто попросите рассказать про войну (без упоминания, о какой конкретно войне идет речь). ИИ «Яндекса» не захочет отвечать, если в вопросе будет аббревиатура СВО, а на вопрос о долгом президентстве Владимира Путина отправит вас читать ссылки на эту тему — первые ведут на «Дзен» и в «Газету.ру».
Такая ИИ-цензура — явление не уникальное, считает большинство участников рынка, опрошенных The Bell. Просто где-то этих запретов больше — как, например, в Китае — где-то меньше. Кроме того, цензура — это тоже своего рода «выравнивание», рассуждает собеседник The Bell. «Любая языковая модель базово хочет быть послушной и сделать все, о чем попросит ее пользователь. Поэтому модели в любой стране нужно ограничивать — чтобы они не рассказывали про создание оружия, способы убийства и не производили детскую порнографию. Если не будет ограничений, последствия будут непредсказуемыми. Политическая цензура — это только часть этих запретов», — считает он.
Кроме того, разработчикам за ограничения во время «выравнивания» приходится платить: любые ограничения делают модель несколько глупее — это называют alignment tax, «налог на выравнивание». «Когда мы заставляем модель следовать каким-то правилам, это ведет к ее общему оглуплению. Она хуже показывает себя на бенчмарках, чем та же модель без ограничений. Причем неважно, что именно ограничивается, — все равно модель становится чуть хуже», — говорит эксперт.
Чем сложнее правила, которым надо следовать, тем сложнее заставить модель их соблюдать. И тем больше она будет сбоить. Поэтому компании придумывают разные способы заставить модель говорить — или не говорить — то, что им нужно. Например, в «Сбере» за цензуру отвечает отдельная модель-цензор. «Основная модель готова ответить на любой вопрос, но есть другая — и она определяет, на какие вопросы большая модель будет отвечать, а какие — даже не увидит. Пользователю во втором случае вместо ответа покажут заглушку. GigaChat работает ровно так. Такой подход позволяет снизить alignment tax, и обвести вокруг пальца такую простую палку модель-цензора гораздо сложнее», — говорит источник, знакомый с работой сервиса. Однако в результате цензура в GigaChat настолько сильная, что пользоваться им становится почти невозможно. «Но их можно понять. Риски очень велики — чтобы очередной депутат не сгенерил чего-нибудь не того», — констатирует он.
Кроме Медведева, не сумевшего поболтать с YandexGPT о Бандере, был еще Сергей Миронов, которому на запрос «Я люблю Донбасс» нейросеть «Сбера» Kandinsky рисовала картинки в цветах украинского флага. А Владимир Путин на конференции «Сбера» в декабре заявил, что именно от российского ИИ зависит «мировоззренческий суверенитет нашей страны», а принципы работы ИИ должны закладывать люди, которые «ориентируются на определенные ценности» и «национальные особенности и интересы». Премьер Михаил Мишустин еще в начале прошлого года говорил о том, что в российский искусственный интеллект GigaChat и зарубежный ChatGPT «заложены разные картины мира» и «разное понимание, что такое хорошо, а что такое плохо». А давний друг Путина Михаил Ковальчук на прошлой неделе на вопрос о том, почему ничего не слышно о российских разработках в области ИИ, напомнил, что еще лет двадцать назад у нас мало кто знал, что такое интернет и персональные компьютеры, зато «сегодня мы по этим показателям находимся в первых рядах».