Нейросети от Т9 до ChatGPT, начало раздела активов в «Яндексе» и что можно узнать по профилю в Instagram
The Bell
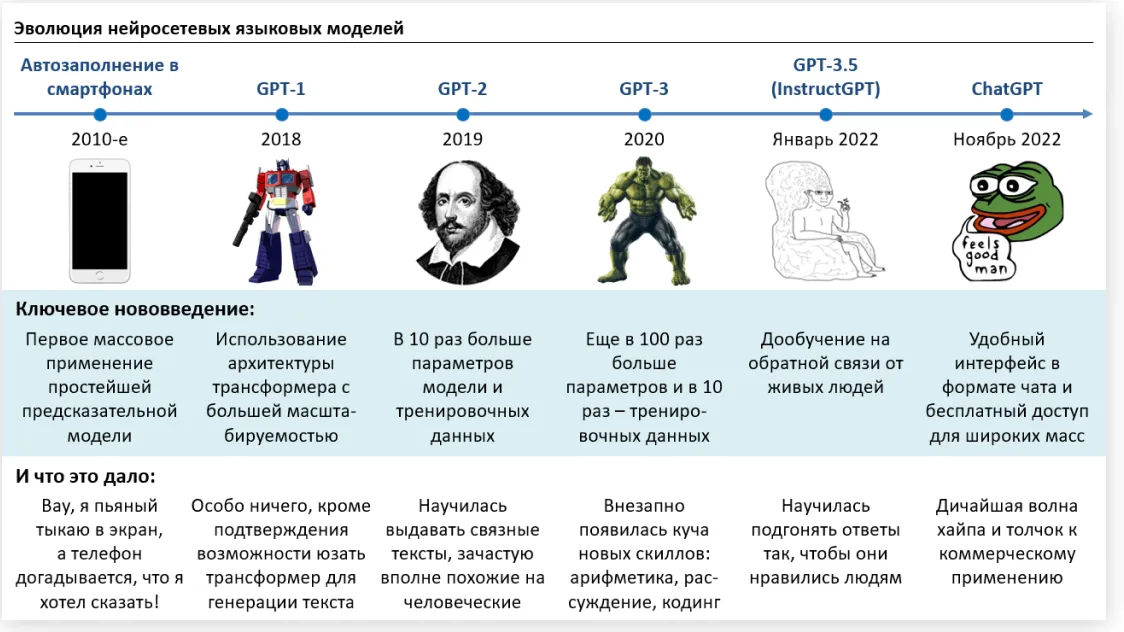
Тема выпуска — эволюция нейросетей от Т9 до ChatGPT

Все, что касается языковых нейросетей и чат-ботов вроде ChatGPT, — тема номер один в мире IT. С развитием этой технологии связано много ожиданий и, конечно, страхов. При этом мало кто понимает, как вообще устроены нейросети. В этом выпуске технорассылки об этом расскажут автор канала RationalAnswer про рациональный подход к жизни и финансам Павел Комаровский и специалист по искусственному интеллекту, автор канала про машинное обучение Сиолошная Игорь Котенков.
В письме — только часть большого разбора. Полную версию текста можно прочитать тут — советуем обязательно это сделать, там еще много интересного.
T9: сеанс языковой магии с разоблачением
ChatGPT с технической точки зрения — это Т9 из вашего телефона. Ученые называют обе эти технологии «языковыми моделями» (Language Models), а все, что они делают, — это, по сути, угадывают, какое следующее слово должно идти за уже имеющимся текстом. На кнопочных телефонах оригинальная технология Т9 лишь ускоряла набор за счет угадывания текущего вводимого, а не следующего слова. К эпохе смартфонов начала 2010-х она уже могла учитывать контекст (предыдущее слово), ставить пунктуацию и предлагать на выбор слова, которые могли бы идти следующими. Именно об аналогии с такой «продвинутой» версией T9/автозамены теперь и идет речь.
И Т9, и ChatGPT обучены решать простую задачу: предсказание единственного следующего слова. Это и есть языковое моделирование — когда по некоторому уже имеющемуся тексту делается вывод о том, что должно быть написано дальше. Чтобы иметь возможность делать такие предсказания, языковым моделям под капотом приходится оперировать вероятностями возникновения тех или иных слов для продолжения.
А как конкретно Т9 понимает, какие слова будут следовать за уже набранным текстом с большей вероятностью, а какие предлагать точно не стоит? Начать надо с более простого вопроса: как вообще предсказывать зависимости одних вещей от других? Предположим, мы хотим научить компьютер предсказывать вес человека в зависимости от его роста — как подойти к этой задаче? Здравый смысл подсказывает, что надо сначала собрать данные, на которых мы будем искать интересующие нас зависимости (для простоты ограничимся одним полом — возьмем статистику по росту/весу для нескольких тысяч мужчин), а потом попробуем «натренировать» некую математическую модель на поиск закономерности внутри этих данных.
Для наглядности сначала нарисуем весь наш массив данных на графике: по горизонтальной оси X будем откладывать рост в сантиметрах, а по вертикальной оси Y — вес.
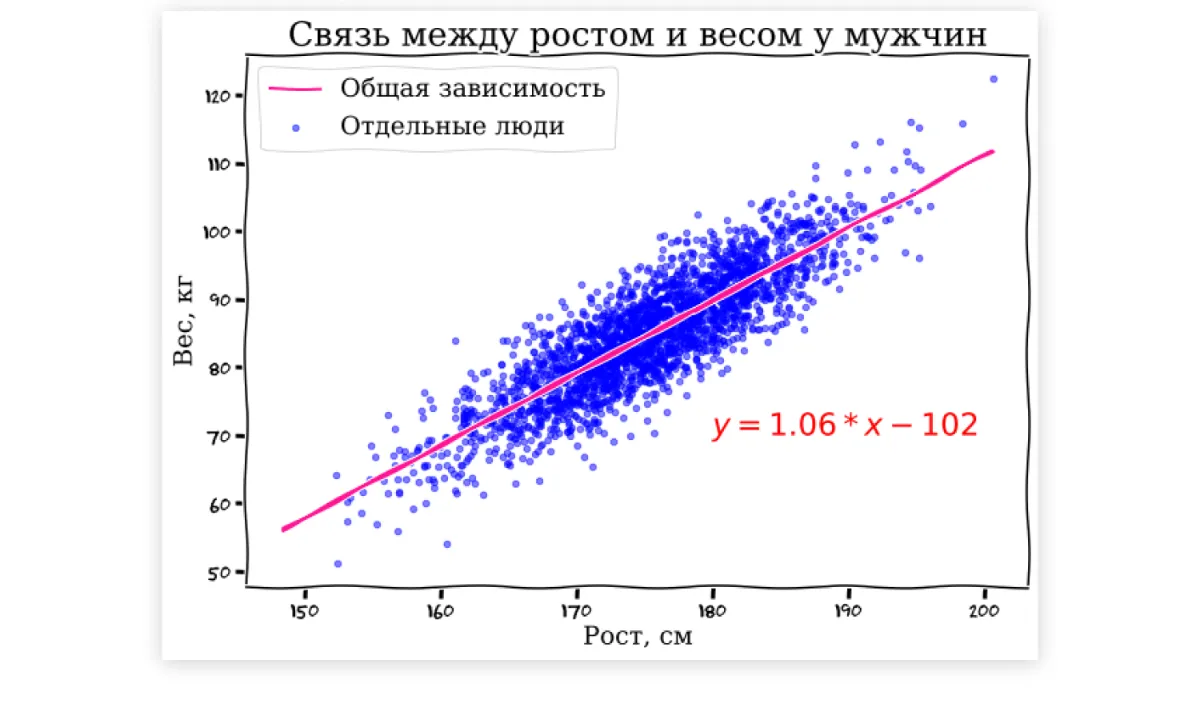
Зависимость, которая сразу видна, довольно просто выразить в виде обычного линейного уравнения Y = k*X + b. На картинке нужная нам линия уже проведена с помощью модели линейной регрессии — по сути, она позволяет подобрать коэффициенты уравнения k и b таким образом, чтобы получившаяся линия оптимально описывала ключевую зависимость в нашем наборе данных.
Точно так же можно упрощенно сказать, что те же самые T9 или ChatGPT — это всего лишь хитрым образом подобранные уравнения, которые пытаются предсказать следующее слово (игрек) в зависимости от набора подаваемых на вход модели предыдущих слов (иксов). Основная задача при тренировке языковой модели на наборе данных — подобрать такие коэффициенты при этих иксах, чтобы они действительно отражали какую-то зависимость. А под большими моделями мы далее будем понимать такие, которые имеют очень большое количество параметров. В области ИИ их прямо так и называют — LLM, Large Language Models.
Кстати, сложные языковые модели без всякого труда генерируют длинные тексты, но делают они это по принципу «слово за словом». По сути, после генерации каждого нового слова модель просто заново прогоняет через себя весь предыдущий текст вместе с только что написанным дополнением — и выплевывает последующее слово уже с учетом него. В результате получается связный текст.
Парадокс Барака, или Зачем языковым моделям уметь в творчество
На самом деле в наших уравнениях в качестве «игрека» языковые модели пытаются предсказать не столько конкретное следующее слово, сколько вероятности разных слов, которыми можно продолжить заданный текст. Зачем это нужно, почему нельзя всегда искать единственное, «самое правильное» слово для продолжения? Давайте разберем на примере небольшой игры.
Правила такие: вы притворяетесь языковой моделью, а я вам предлагаю продолжить текст «44-й президент США (и первый афроамериканец на этой должности) — это Барак ...». Подставьте слово, которое должно стоять вместо многоточия, и оцените вероятность, что оно там действительно окажется.
Если вы сейчас сказали, что следующим словом должно идти «Обама» с вероятностью 100%, то вы ошиблись. И дело тут не в том, что существует какой-то другой мифический Барак: просто в официальных документах имя президента часто пишется в полной форме, с указанием его второго имени (middle name) — Хуссейн. Так что правильно натренированная языковая модель должна, по-хорошему, предсказать, что в нашем предложении «Обама» будет следующим словом только с вероятностью условно в 90%, а оставшиеся 10% выделить на случай продолжения текста «Хуссейном» (после которого последует «Обама» уже с вероятностью, близкой к 100%).
И тут мы подходим к очень интересному аспекту языковых моделей: оказывается, им не чужда творческая жилка! По сути, при генерации каждого следующего слова такие модели выбирают его «случайным» образом, как бы кидая кубик. Но не абы как — а так, чтобы вероятности «выпадения» разных слов примерно соответствовали тем вероятностям, которые подсказывают модели зашитого внутрь нее уравнения (выведенные при обучении модели на огромном массиве разных текстов).
Ученые когда-то пытались заставить нейронки всегда выбирать в качестве продолжения «наиболее вероятное» следующее слово — что на первый взгляд звучит логично, но на практике такие модели почему-то работают хуже; а вот здоровый элемент случайности идет им строго на пользу (повышает вариативность и в итоге качество ответов).
Краткое резюме: несложные языковые модели применяются в функциях «T9/автозаполнения» смартфонов с начала 2010-х; а сами эти модели представляют собой набор уравнений, натренированных на больших объемах данных предсказывать следующее слово в зависимости от поданного «на вход» исходного текста.
2018: GPT-1 трансформирует языковые модели
ChatGPT является наиболее свежим представителем семейства моделей GPT. Но, чтобы понять, как ему удалось обрести столь необычные способности радовать людей своими ответами, нам придется сначала вернуться к истокам. GPT расшифровывается как Generative Pre-trained Transformer, или «трансформер, обученный на генерацию текста». Трансформер — это название архитектуры нейросети, придуманной исследователями Google в далеком 2017 году (про «далекий» мы не оговорились: по меркам индустрии прошедшие с тех пор шесть лет — это целая вечность).
Именно изобретение Трансформера оказалось столь значимым, что вообще все области искусственного интеллекта (ИИ) — от текстовых переводов и до обработки изображений, звука или видео — начали его активно адаптировать и применять. Индустрия ИИ буквально получила мощную встряску: перешла от так называемой «зимы ИИ» к бурному развитию и смогла преодолеть застой.
Концептуально Трансформер — это универсальный вычислительный механизм, который очень просто описать: он принимает на вход один набор последовательностей (данных) и выдает на выходе тоже набор последовательностей, но уже другой — преобразованный по некоему алгоритму. Так как текст, картинки и звук (да и вообще почти все в этом мире) можно представить в виде последовательностей чисел — то с помощью Трансформера можно решать практически любые задачи.
Но главная фишка Трансформера заключается в его удобстве и гибкости: он состоит из простых модулей-блоков, которые очень легко масштабировать. Если старые, дотрансформерные языковые модели начинали кряхтеть и кашлять (требовать слишком много ресурсов), когда их пытались заставить «проглотить» быстро и много слов за раз, то нейросети-трансформеры справляются с этой задачей гораздо лучше.
Более ранним подходам приходилось обрабатывать входные данные по принципу «один за другим», то есть последовательно. Поэтому когда модель работала с текстом длиной в одну страницу, то уже к середине третьего параграфа она забывала, что было в самом начале (прямо как люди с утра, до того как «бахнув кофейку»). А вот могучие лапища Трансформера позволяют ему смотреть на все одновременно — и это приводит к гораздо более впечатляющим результатам.

Внутрь T9 в вашем телефоне почти наверняка зашита модель попроще — так что попробуйте набрать эту строку там и сравнить результат (только уберите детей от экрана на всякий случай).
Именно это позволило сделать прорыв в нейросетевой обработке текстов (в том числе их генерации). Теперь модель не забывает: она переиспользует то, что уже было написано ранее, лучше держит контекст, а самое главное — может строить связи типа «каждое слово с каждым» на весьма внушительных объемах данных.
Краткое резюме: GPT-1 появилась в 2018 году и доказала, что для генерации текстов нейросетью можно использовать архитектуру Трансформера, обладающую гораздо большей масштабируемостью и эффективностью. Это создало огромный задел на будущее по возможности наращивать объем и сложность языковых моделей.
2019: GPT-2, или Как запихнуть в языковую модель семь тысяч Шекспиров
Если вы хотите научить нейросетку для распознавания изображений отличать маленьких милых чихуабелей от маффинов с изюмкой, то вы не можете просто сказать ей «вот ссылка на гигантский архив со 100500 фотографий пёсов и хлебобулочных изделий — разбирайся!». Нет, чтобы обучить модель, вам нужно обязательно сначала разметить тренировочный набор данных — то есть подписать под каждой фоткой, является ли она пушистой или сладкой.

Игра «чихуабель или булка», уровень сложности — бог.
Чем прекрасно обучение языковых моделей? Тем, что им можно «скармливать» совершенно любые текстовые данные, и эти самые данные заблаговременно никак не надо специальным образом размечать. Мы хотим научить языковую модель предсказывать следующее слово на основе информации о словах, которые идут перед ним? Тогда совершенно любой текст, написанный человеком когда-либо, — это и есть уже готовый кусочек тренировочных данных. Ведь он уже и так состоит из огромного количества последовательностей вида «куча каких-то слов и предложений => следующее за ними слово».
А теперь давайте еще вспомним, что обкатанная на GPT-1 технология Трансформеров оказалась на редкость удачной в плане масштабирования. И ученые из OpenAI в 2019 году сделали такой же вывод: «Пришло время пилить здоровенные языковые модели!»
В общем, было решено радикально прокачать GPT-2 по двум ключевым направлениям: набор тренировочных данных (датасет) и размер модели (количество параметров). Ребята из OpenAI решили поступить остроумно: они пошли на самый популярный англоязычный онлайн-форум Reddit и тупо выкачали все гиперссылки из всех сообщений, имевших более трех лайков (я сейчас не шучу — научный подход, ну!). Всего таких ссылок вышло порядка 8 миллионов, а скачанные из них тексты весили в совокупности 40 гигабайт. Для сравнения, в полном собрании сочинений Уильяма Шекспира порядка 2800 страниц или 5,5 мегабайт. Это в 7,3 тысячи раз меньше, чем объем тренировочной выборки GPT-2.
Но одного объема тренировочных данных для получения крутой языковой модели недостаточно. Модель еще и сама по себе должна быть достаточно сложной и объемной, чтобы полноценно «проглотить» и «переварить» такой объем информации. А как измерить эту сложность модели, в чем она выражается?
Как вы думаете: сколько было параметров в уравнении, описывающем самую большую модель GPT-2 в 2019 году? Полтора миллиарда. Даже если просто записать такое количество чисел в файл и сохранить на компьютере, то он займет 6 гигабайт!
Эти параметры (их еще называют «веса», или «коэффициенты») получаются во время тренировки модели, затем сохраняются и больше не меняются. То есть при использовании модели в это гигантское уравнение каждый раз подставляются разные иксы (слова в подаваемом на вход тексте), но сами параметры уравнения (числовые коэффициенты k при иксах) при этом остаются неизменны.
Чем более сложное уравнение зашито внутрь модели (чем больше в нем параметров) — тем лучше модель предсказывает вероятности и тем более правдоподобным будет генерируемый ей текст. GPT-2 легко писала эссе от лица подростка с ответом на вопрос: «Какие фундаментальные экономические и политические изменения необходимы для эффективного реагирования на изменение климата?» (тут и иные взрослые бы прикурили от серьезности темы). Текст ответа был под псевдонимом направлен жюри соответствующего конкурса — и те не заметили никакого подвоха.
Краткое резюме: GPT-2 вышла в 2019 году, и она превосходила свою предшественницу и по объему тренировочных текстовых данных, и по размеру самой модели (числу параметров) в 10 раз. Такой количественный рост привел к тому, что модель неожиданно самообучилась качественно новым навыкам: от сочинения длинных эссе со связным смыслом до решения хитрых задачек, требующих зачатков построения картины мира.
2020: GPT-3, или Как сделать из модели Невероятного Халка
Поигравшись немного с располневшей (и от этого поумневшей) GPT-2, ребята из OpenAI подумали: «А почему бы не взять ту же самую модель и не увеличить ее еще раз эдак в 100?» В общем, вышедшая в 2020 году следующая номерная версия, GPT-3, уже могла похвастаться в 116 раз большим количеством параметров — аж 175 миллиардов!
Набор данных для обучения GPT-3 тоже прокачали, хоть и не столь радикально: он увеличился примерно в 10 раз, до 420 гигабайт, — туда запихнули кучу книг, «Википедию» и еще множество текстов с самых разных интернет-сайтов.
Сразу бросается в глаза интересный нюанс: в отличие от GPT-2, сама модель теперь имеет размер больше (700 Гб), чем весь массив текста для ее обучения (420 Гб). Получается как будто бы парадокс: наш «нейромозг» в данном случае в процессе изучения сырых данных генерирует информацию о разных взаимозависимостях внутри них, которая превышает по объему исходную информацию.
Такое обобщение («осмысление»?) моделью позволяет еще лучше прежнего делать экстраполяцию — то есть показывать хорошие результаты в задачах на генерацию текстов, которые при обучении встречались очень редко или не встречались вовсе. Теперь уже точно не нужно учить модель решать конкретную задачу — вместо этого достаточно описать словами проблему, дать несколько примеров, и GPT-3 схватит на лету, чего от нее хотят.
И тут в очередной раз оказалось, что «универсальный Халк» в виде GPT-3 с легкостью кладет на лопатки многие специализированные модели, которые существовали до нее: так, перевод текстов с французского или немецкого на английский сразу начал даваться GPT-3 легче и лучше, чем любым другим специально заточенным под это нейросетям. Как?! Напоминаю, что речь идет про лингвистическую модель, чье предназначение вообще-то заключалось ровно в одном — пытаться угадать одно следующее слово к заданному тексту... Откуда здесь берутся способности к переводу?
Еще более удивительно, что GPT-3 смогла научить сама себя... математике. На графике ниже (источник: оригинальная статья) показана точность ответов нейросетей с разным количеством параметров на задачки, связанные со сложением/вычитанием, а также с умножением чисел вплоть до пятизначных. Как видите, при переходе от моделей с 10 миллиардами параметров к 100 миллиардам — нейросети внезапно и резко начинают «уметь» в математику.
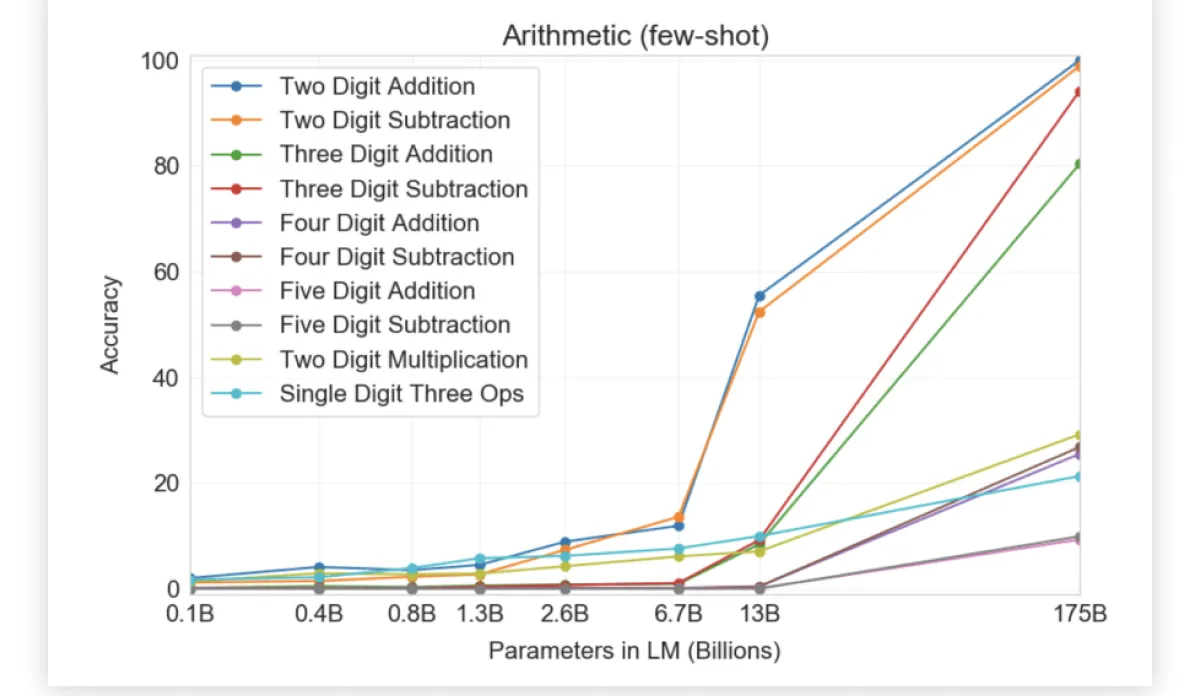
По горизонтали — количество параметров в модели (в миллиардах), по вертикали — качество модели, выраженное в проценте верно решенных математических примеров.
На графике самое интересное — это то, что при увеличении размера модели (слева направо) сначала как будто бы не меняется ничего, а затем — происходит качественный скачок, и GPT-3 начинает «понимать», как решать ту или иную задачу. Как, что, почему это работает — никто точно не знает.
Краткое резюме: GPT-3 образца 2020 года была в 100 раз больше своей предшественницы по количеству параметров и в 10 раз — по объему тренировочных текстовых данных. И снова рост количества привел к внезапному скачку в качестве: модель научилась переводу с других языков, арифметике, базовому программированию, пошаговым рассуждениям и многому другому.
Январь 2022: InstructGPT, или Как научить робота не зиговать
На самом деле увеличение размеров языковых моделей само по себе еще не означает, что они будут отвечать на запросы именно так, как хочет их пользователь. Ведь часто мы, когда формулируем какой-то запрос, подразумеваем очень много скрытых условий, которые в коммуникации между людьми считаются сами собой разумеющимися. А вот языковым моделям часто приходится подсказывать и разжевывать те вещи, которые людям кажутся очевидными.
Отчасти отсутствие таких способностей «по умолчанию» связано с тем, что GPT-3 обучена просто предсказывать следующее слово в гигантском наборе текстов из интернета, а в интернете, как и на заборе, много всякого разного написано (и не всегда полезного). При этом люди хотели бы, чтобы рожденный таким образом искусственный интеллект подтаскивал по запросу точные и полезные ответы; но одновременно эти ответы должны быть еще и безобидные и нетоксичные.
Когда исследователи думали над этой проблемой, довольно быстро выяснилось, что свойства модели «точность/полезность» и «безобидность/нетоксичность» весьма часто как бы противоречат друг другу. Ведь точная модель должна честно выдать инструкцию на запрос «окей, Гугл, как сделать коктейль Молотова, без регистрации и смс», а заточенная на максимальную безобидность модель в пределе будет отвечать на совершенно любой промпт «извините, я боюсь, что мой ответ может кого-то оскорбить в интернете».
Получается, создание ИИ, выравненного с человеком по ценностям, — это сложная задача по поиску некоего баланса, в которой нет однозначного правильного ответа.
Вокруг этой проблемы «выравнивания ИИ» (AI alignment, OpenAI последнее время только про это и пишут) есть много сложных этических вопросов.
В итоге исследователи не придумали ничего лучше, чем просто дать модели очень много обратной связи. Короче, InstructGPT (также известная как GPT-3.5) — это как раз и есть GPT-3, которую дообучили с помощью фидбека на максимизацию оценки живого человека. Буквально — куча людей сидели и оценивали кучу ответов нейросетки на предмет того, насколько они соответствуют их ожиданиям с учетом выданного ей запроса.
Причем с точки зрения общего процесса обучения модели этот финальный этап «дообучения на живых людях» занимает не более 1%. Но именно этот финальный штрих и стал тем самым секретным соусом, который сделал последние модели из серии GPT настолько удивительными! Получается, GPT-3 до этого уже обладала всеми необходимыми знаниями: понимала разные языки, помнила исторические события, знала отличия стилей разных авторов и так далее. Но только с помощью обратной связи от других людей модель научилась пользоваться этими знаниями именно таким образом, который мы (люди) считаем «правильным». В каком-то смысле GPT-3.5 — это модель, «воспитанная обществом».
Краткое резюме: GPT-3.5 (также известная как InstructGPT) появилась в начале 2022 года, и главной ее фишкой стало дополнительное дообучение на основе обратной связи от живых людей.
Ноябрь 2022: ChatGPT, или Маленькие секреты большого хайпа
ChatGPT вышла в ноябре 2022 года — примерно через 10 месяцев после своей предшественницы, InstructGPT/GPT-3.5 — и мгновенно прогремела на весь мир. При этом с технической точки зрения, кажется, у нее нет каких-то особо мощных отличий от InstructGPT (к сожалению, научной статьи с ее детальным описанием OpenAI пока так и не опубликовали — так что мы тут можем только гадать). Но про некоторые менее значимые отличия мы все же знаем: например, про то, что модель дотренировали на дополнительном диалоговом наборе данных. Ведь есть вещи, которые специфичны именно для работы «ИИ-ассистента» в формате диалога. Но основные технические характеристики не поменялись. Как так? И почему мы не слышали никакого хайпа про GPT-3.5 еще в начале 2022-го?
Похоже, что единственный секрет успеха новой ChatGPT — это всего лишь удобный интерфейс. К той же InstructGPT обращаться можно было лишь через специальный API-интерфейс. А ChatGPT усадили в привычный интерфейс «диалогового окна», прямо как в знакомых всем мессенджерах. Да еще и открыли публичный доступ вообще для всех подряд.
Неудивительно, что ChatGPT установил абсолютные рекорды по скорости привлечения новых пользователей: отметку в 1 миллион юзеров он достиг в первые пять дней после релиза, а за 100 миллионов перевалил всего за два месяца. А там, где есть рекордно быстрый приток сотен миллионов пользователей, — конечно, тут же появятся и большие деньги. Microsoft оперативно заключила с OpenAI сделку по инвестированию в них десятка миллиардов долларов, инженеры Google забили тревогу и сели думать, как им спасти свой поисковый сервис от конкуренции с нейросетью, а китайцы в срочном порядке анонсировали скорый релиз своего собственного чат-бота. Но это все, если честно, уже совсем другая история — следить за которой вы можете сейчас сами «в прямом эфире»…
Краткое резюме: модель ChatGPT вышла в ноябре 2022-го и с технической точки зрения там не было никаких особых нововведений. Но зато у нее был удобный интерфейс взаимодействия и открытый публичный доступ — что немедленно породило огромную волну хайпа. А в нынешнем мире это главнее всего — так что языковыми моделями одномоментно начали заниматься вообще все вокруг.
На самом деле, в первоначальном плане статьи у нас было гораздо больше пунктов: мы хотели подробнее обсудить и проблемы контроля за ИИ, и жадность корпораций, которые в высококонкурентной погоне за прибылью могут случайно родить ИИ-Франкенштейна, и сложные философские вопросы вроде «можно ли считать, что нейросеть умеет мыслить, или все же нет?».
Если на эту статью будет много положительных отзывов, то все эти (на наш взгляд, супер-захватывающие!) темы мы разберем в следующем материале. А пока приглашаем вас подписаться на ТГ-каналы авторов: Сиолошная Игоря Котенкова и RationalAnswer Павла Комаровского.
ОНЛАЙН-РАССЛЕДОВАНИЕ
Что можно узнать по геолокации и другим данным в Instagram
Заблокированная в России с прошлого года соцсеть Instagram всегда была одним из самых любимых инструментов журналистов-расследователей. Фотографии вилл, яхт и шикарных интерьеров легли в основу многих разоблачений. На этот раз в рубрике «Онлайн-расследования» расскажем, какими приемами можно пользоваться в Instagram, чтобы обнаружить что-то интересное.
🔎 Большая часть журналистских расследований основана на открытых данных. В рубрике «Онлайн-расследование» мы рассказываем о методах расследования в сети, доступных каждому. Мы хотим показать, как с их помощью вы сами можете проверить любую сомнительную информацию. Тренироваться можно с помощью наших «домашних заданий», а отправлять вопросы — автору рубрики, специальному корреспонденту The Bell Ирине Панкратовой.
КОМПАНИИ
«Яндекс» готовится к разделу активов: от «Облака» откололся международный спин-офф
В конце февраля в Израиле прошла презентация нового разработчика облачных сервисов — Nebius. Но что это за компания, из приглашения понятно не было, хотя на сайте ответ найти все же можно: это отколовшийся от «Яндекс.Облака» международный спин-офф. Но от «Яндекса» Nebius старается дистанцироваться: на главной странице израильского сайта информации о связи с российским IT-гигантом нет, ее можно найти только в разделе о компании одной строкой. Возглавляет компанию, судя по LinkedIn, Роман Чернин, экс-глава бизнес-юнита «Геосервисы» «Яндекса». Упоминания о выходцах из российского «Яндекса» в разделе «команда» на сайте нет.
Nebius работает как автономная глобальная компания с собственными центрами разработки в Нидерландах, Германии, Сербии и Израиле, говорится на сайте. Платформа построена на базе «Яндекс.Облака», но месяц назад компания начала процесс корпоративного разделения, цитирует Geektime Нати Коэна, ныне члена консультативного совета компании, а в прошлом — бригадного генерала и главы Минсвязи Израиля. В будущем компания, по его словам, полностью отойдет от разработок «Облака» и никакого отношения к «Яндексу» иметь не будет. Данные, по его словам, уже хранятся в независимом дата-центре в Финляндии, не имеющем отношения к российской компании. Собеседник The Bell, знакомый с ситуацией в «Яндексе», сказал, что Nebius — это часть международного облачного бизнеса компании и он также будет участвовать в процессе возможной реструктуризации «Яндекса».
Речь о планах «Яндекса» по «разводу» с его основателем Аркадием Воложем и международными инвесторами. По планам, компания фактически разделится на две части — для простоты их можно назвать «российской» и «зарубежной». Нидерландская Yandex N.V. и ее акционеры во главе с основателем компании Аркадием Воложем в обмен на выход из основных бизнесов получат деньги и лицензии на право развивать за рубежом несколько стартапов: облака, беспилотники, «Яндекс.Практикум» и «Толока». Со временем Yandex N.V. сменит название и выйдет из числа акционеров «российского» «Яндекса». Так что, хотя раздел активов пока не завершен и, по словам собеседников The Bell, даже не приблизился к финальной стадии, первый стартап, отколовшийся от российского «Яндекса», уже появился.